
* pubblicato sulla rivista Quaderni della decrescita https://quadernidelladecrescita.it/2024/05/06/la-governance-algoritmica-del-capitalismo-computazionale-una-prospettiva-critica/
La governance algoritmica del capitalismo computazionale.
Una prospettiva critica
di Alvise Marin
Abstract. La rivoluzione tecnologica del digitale e più ancora i suoi ultimi prodotti sociotecnici, quali social network, big data, realtà aumentata, algoritmi e intelligenza artificiale, in particolar modo quella generativa conversazionale come ChatGpt, è arrivata a costruire un esoscheletro digitale, il quale sta riconfigurando società, economia, politica e guerra, giù giù fino all’identità e alla psiche dei singoli individui. Lontani da ogni atteggiamento neoluddista, che si auspichi un nostalgico e impossibile ritorno al passato, sorge la necessità di una interpretazione, di un governo e di una riconfigurazione della tecnologia digitale, che abbia l’obiettivo di restituire alla persona le facoltà di sentire e pensare autonomamente, cosa che oggi, a nostro modo di vedere, risulta a rischio. Tecnologia da sottoporre quindi a una preventiva disamina ermeneutica, per verificare se essa possieda la doppia valenza significativa del pharmakon, in quanto insieme veleno e cura possibile o se altrimenti, contenga già nel suo concepimento il dettato capitalistico, che ne farebbe lo strumento affinché quest’ultimo sistema possa continuare a perpetuarsi.
Sommario: Introduzione – 1. Dalla società di controllo alla società automatica del Capitalismo 4.0 – 2. Big Data, algoritmi e IA come nuovi strumenti del tecno-capitalismo – 3. Lavoro, ambiente e conflitti armati nell’epoca dell’intelligenza artificiale – 4. Disautomatizzare e ripoliticizzare il desiderio. Per un’estetica desiderante – Conclusioni
Parole chiave: tecnocapitalismo; società del controllo; società automatica; big data; algoritmi; intelligenza artificiale; desiderio; estetica
Il capitale è un vortice nichilista automatizzante che neutralizza tutti i valori tramite commisurazione al commercio digitalizzato, e che guida una migrazione dal comando dispotico al controllo cyber-sensibile: da status e significato a moneta e informazione. Nick Land, Collasso
Il passato è latente, sommerso, ma ancora qui, capace di tornare in superficie non appena l’ultima maschera, attraverso qualche malaugurato incidente, svanisce nel nulla. Philip K. Dick Ubik
Abbiamo bisogno di molto lavoro di invenzione per ripensare radicalmente il sapere, i modelli teorici dominanti e l’interpretazione della realtà. Bernard Stiegler
Introduzione.
Quali possibilità di privacy e libertà rimangono al singolo e alla collettività nel cosiddetto «capitalismo della sorveglianza», che oggi dovremmo chiamare, con le parole di Bernard Stiegler, «capitalismo computazionale», dove il controllo è invisibile perché legato alle infinite impronte digitali che lasciamo anche solo con uno smartphone in tasca, navigando nel web, o usando una carta di credito, sotto l’occhio vigile e ubiquitario di telecamere, che ormai si confondono con il paesaggio urbano, dove la non libertà, non avendo più la necessità di essere coercitiva, viene proprio per questo scambiata per libertà? È ancora possibile tornare a interpellare il nostro desiderio singolare, sottraendosi agli automatismi e al controllo degli algoritmi che, anticipandolo e standardizzandolo attraverso gruppi e segmenti di consumo, lo conducono verso quell’estinzione, che lascia sul campo un coacervo di pulsioni acefale che producono passaggi all’atto senza sublimazione e formulazione di desiderio?
Il «capitalismo computazionale», andando sempre più veloce del diritto, lo anticipa e lo previene, imponendo uno stato di fatto algoritmico, che necessita di essere sempre ricondotto nell’alveo di una norma giuridica. Una norma però, come l’IA act promulgato il 13 marzo 2024, dal parlamento europeo, che non può che arrivare in ritardo, sempre superata dalla velocità dei mutamenti della IA, che cambia di giorno in giorno. Sottrarre la tecnologia digitale e l’IA in particolare, al comando capitalistico, che norma e istituzionalizza da sempre ciò che gli serve per riprodursi, necessita di una insorgente presa di coscienza da parte di ognuno dei molti, che dibattano pubblicamente sui suoi rischi e opportunità, laddove ce ne siano, avviando forme costituenti di riconfigurazione dell’uso e dell’implementazione della tecnologia digitale, nella direzione di un suo impiego per il benessere di tutti gli esseri viventi. Per fare questo è necessario che «l’automatizzazione di fatto sia messa di diritto al servizio della capacità di disautomatizzare» (Stiegler, 2019, p. 365). Al di là di un nostalgico e impossibile ritorno al passato, sorge la necessità di un governo della tecnica, che abbia l’obiettivo di restituire ad ogni persona le facoltà di sentire e pensare autonomamente, oggi minacciate più che mai e al contesto sociale simbolico-culturale quello di offrire, contro la standardizzazione del Sé, la possibilità di una individuazione singolare di ogni soggetto umano. La delega parziale ad algoritmi e Intelligenza Artificiale (IA) di alcune operazioni dell’intelletto, quali il calcolo numerico, che possono essere effettuate in modo più efficiente dalle macchine digitali, deve essere diretta dalla «vocazione sintetica» della ragione, la quale riconduca queste operazioni, in un contesto ermeneutico che ne assegni priorità e fini. Il tecno-capitalismo digitale, rimanendo all’interno del paradigma dell’accumulazione, è un «capitalismo all’ennesima potenza», che ha sempre in vista più produzione, più produttività, più consumi e più profitti che, aldilà di green-washing e work-washing, significano anche più riscaldamento climatico e più precarietà. L’interrogativo da porsi è se l’IA una volta sottratta allo statuto oracolare di risolutore di ogni problema e all’attrazione nell’orbita di un modello capitalista estrattivo, che la utilizza nell’accumulo di profitti e rendite, senza alcuna considerazione per i possibili ritorni negativi a livello sociale, economico-finanziario e militare, potrebbe risultare utile per il benessere individuale, collettivo e del pianeta che ci ospita. La possibilità di affiancare l’essere umano, sotto la sua supervisione, come avviene già oggi, o di sostituirlo come potrebbe accadere in futuro, in operazioni su grandi moli di dati, che possano essere svolte con più velocità e precisione, per ricavarvi tendenze e modelli inferenziali, è una strada che si dovrebbe continuare a percorrere? Oppure rischieremo, come avviene in un racconto di Asimov intitolato Nove volte sette1, l’atrofizzazione della memoria, con la conseguente incapacità di svolgere quelle operazioni elementari del passato che ora sono automatizzate? Un rischio che corrono soprattutto le giovani generazioni, abituate a delegare alla macchina ogni calcolo schiacciando un tasto, o a interrogare ChatGpt per ottenere qualunque risposta senza sforzo, con una soglia di attenzione in drastica diminuzione e l’incapacità di ritenere informazioni senza trascriverle passo passo.
Se l’IA può venire utilizzata nella diagnostica strumentale in ambito sanitario, nelle previsioni sul cambiamento climatico, nella prevenzione e gestione dei disastri, allo stesso tempo viene da chiedersi quanti saperi sapienziali vernacolari andranno dimenticati e cancellati e quanti disastri ambientali e climatici si sarebbero potuti evitare, intervenendo a monte di un sistema economico, quello capitalistico, che producendoli, tende a perpetuarsi anche grazie a loro, attraverso la perenne invocazione di uno stato di emergenza?
Il fatto che l’IA rimanga ancorata al suo statuto strumentale, senza assumere una veste oracolare o contribuire a generare sfruttamento economico, disarticolazione sociale, rendite di posizione, polarizzazione della conoscenza e del potere politico, aumento dell’entropia ambientale e ancora, divenga la tecnologia sempre più utilizzata in modo autonomo nei futuri conflitti militari combattuti solo da macchine, ma con più morti “civili”, che rimangono l’obiettivo delle guerre, aprendo un precipizio ancora più profondo di quello in cui noi oggi ci troviamo e mettendo a rischio la sopravvivenza dell’umanità intera, dipende dal suo venire condivisa e collettivizzata a livello globale, dal suo essere open-source, dal considerare i Big Data come un bene comune non privatizzabile, verso una direzione che sia altermondialista e anticapitalista. Questo nel caso si voglia assumere la doppia valenza significativa che Stiegler assegna alla tecnica, nella sua veste di pharmakon, insieme veleno e possibile cura.
1. Dalla società di controllo alla società automatica del Capitalismo 4.0.
Gilles Deleuze, nel suo Poscritto sulle società di controllo pubblicato nel 1990, scriveva di come la società di controllo avesse preso il posto della società disciplinare. Una società, quella di controllo, che conteneva in sé già i prodromi e gli elementi che saranno alla base del salto tecnologico compiuto nell’ultima decade del ‘900, quello che corrisponde alla nascita nel 1993 del World Wide Web che segnerà, secondo Stiegler, un primo passo verso l’attuale società automatica, quella propria del capitalismo 4.0. Web, che nei primi anni Duemila, nella sua versione 2.0, comincia a usare nuove tecnologie informatiche che permettono di costruire siti dinamici, rapidamente e costantemente aggiornabili, con una comunicazione e una interazione bidirezionale con l’utente, il quale non è più solo fruitore ma diventa sempre più autore dei suoi contenuti. Blog, forum, chat e sistemi come Wikipedia e Youtube, fino alla svolta dei social network, primo fra tutti Facebook, rendono possibile immettere e condividere in rete quantità esponenzialmente crescenti di testi, foto e video. È a partire da qui che la raccolta di informazioni sugli utenti, attraverso tecniche di profilazione, diventa occasione per generare profitti a beneficio delle società che forniscono servizi gratuiti online, le quali poi commercializzano questi dati. Dati che diventano anche la risorsa più importante con la quale addestrare gli stessi algoritmi di IA che servono a profilare gli utenti del web. Secondo il collettivo Into the Black Box, tra i processi che caratterizzano il capitalismo 4.0 ci sono «l’imporsi dell’industria dell’Information Technology, […] la recente rapida crescita del capitalismo delle piattaforme, […] la ricerca di un aumento di produttività tramite l’integrazione di sistemi cyber-fisici nei processi industriali (un ecosistema di risorse fisiche e virtuali), il divenire “smart” di produzione e distribuzione (mix tecnologico di automazione, informazione, connessione e programmazione) di un capitalismo dispiegato a livello planetario lungo supply chain e catene globali del valore; più in generale, l’innesto nel quotidiano di robotica, Internet of Things (IoT), Intelligenza Artificiale (IA), dimensione algoritmica».
Il capitalismo 4.0 di Into the Black Box e la società automatica di Bernard Stiegler, frutto della rivoluzione digitale, appartengono per entrambi all’epoca iperindustriale, quella in cui i «processi sociali e produttivi si sovrappongono e confondono grazie all’intermediazione dell’algoritmo […] e il “modo industriale” esce dalla fabbrica per insinuarsi nella riproduzione sociale, nella sfera dei consumi o nell’ambito politico» (Into the black box, 2021, pp. 9-12).
La nostra epoca realizza la visionaria previsione di Marx, quella che troviamo nel Quaderno VI dei Grundrisse: «una volta accolto nel processo produttivo del capitale, il mezzo di lavoro percorre diverse metamorfosi, di cui l’ultima è la macchina o, piuttosto, un sistema automatico di macchine (sistema di macchine; quello automatico è solo la forma più perfetta e adeguata del macchinario, che sola lo trasforma in un sistema), messo in moto da un automa, forza motrice che muove sé stessa; questo automa consistente di numerosi organi meccanici e intellettuali, in modo che gli operai stessi sono determinati solo come organi coscienti di esso» (Marx, 1970, II, pp. 389, 390). All’interno dell’apparato tecnico e dell’automa cognitivo globali, il soggetto umano è oggi diventato solo una delle loro componenti, «un organo cosciente», che si è trasformato in un «funzionario della tecnica» e, in ultima istanza, del sistema capitalistico, che la comanda.
L’identità dell’individuo si risolve nel suo essere funzionale all’apparato tecnico, che come una potenza autonoma, regola la vita degli uomini, e la tecnica, nata per sottrarre l’uomo alla necessità della natura, diventa a sua volta una seconda natura, non meno necessitante della prima (Galimberti, 1999, p. 557).
Lo stesso desiderio e la cooperazione sociale, fondamento dell’intelligenza collettiva (general intellect), che dal pensiero marxista, segnatamente quello “operaista”, erano intesi come terreni di soggettivazione antagonista al comando capitalista, vengono sussunti e plasmati da quest’ultimo, addestrando le piattaforme digitali e le più recenti tecnologie di IA, all’estrazione di valore. La società iperindustriale porta con sé una riorganizzazione del lavoro, in direzione di una sua parcellizzazione e autonomizzazione, tramite piattaforme digitali, che coordinano crowdworking e lavoretti digitali (gig works) e un abbattimento della frontiera che divideva l’uomo dalla macchina, in direzione di una forma di lavoro, il cyber-lavoro, nella quale essi risultano integrati, potenziati, misurati e monitorati. Nei magazzini della logistica di Amazon, i processi lavorativi vengono frammentati in micro-operazioni eso-strutturate, in modo tale da modellare e monitorare gesti, movimenti e sforzo nervoso degli operatori che vi lavorano.
Ci si è avviati verso la macchinizzazione del vivente, la cui vita quotidiana è sempre più supportata da strumenti digitali, e la vivificazione della macchina, la quale svolge un numero sempre maggiore di attività che una volta appartenevano all’essere umano, in direzione di una soggettività macchinica. Un esoscheletro digitale potenzia le capacità della forza lavoro, penetrando contemporaneamente nella produzione, nei consumi, nella socialità e nella riproduzione. IoT, Big Data, realtà virtuale, IA, cloud e robotica evoluta «concorrono a formare ambienti che hanno in comune l’incorporamento di istruzioni digitali (algoritmi) e punti di connessione abilitanti il dialogo tra mondo fisico, umani, macchine, ridefinendo logiche organizzative e pratiche individuali e collettive, nel lavoro come nella più generale sfera sociale» (Into the black box, 2021, pp. 26-35). Gli algoritmi stanno ormai alla base del mondo della produzione industriale, come della società nelle sue modalità di consumo e di relazione. Le macchine digitali al cui interno sono codificati, diventano altrettante scatole nere nelle quali sono cristallizzati asimmetrie di potere, che formattando abitudini e comportamenti degli individui, diventano strutture d’ordine della società.
Nel mondo degli algoritmi anche la stessa distinzione tra reale e virtuale viene a cadere, laddove l’utilizzo di Gps, mappe online, telecamere intelligenti e realtà aumentata producono uno spazio ibrido nel quale le due dimensioni si integrano e si sovrappongono.
2. Big Data, algoritmi e IA come nuovi strumenti del tecno-capitalismo.
Big Data, algoritmi e nuova IA sono intimamente legati l’uno all’altro. È infatti a partire dall’enorme disponibilità di dati, resa possibile dalla nascita del Web e dalla crescita esponenziale della potenza di calcolo delle macchine digitali, che ha reso gli algoritmi sempre più performanti, che ha preso avvio la nuova IA.
Risale alla fine degli anni novanta del secolo scorso, il cambio di paradigma relativo allo studio e all’implementazione dell’intelligenza artificiale, quello della data-driven AI (IA basata sui dati). Il paradigma precedente, quello della «Intelligenza artificiale simbolica», si manteneva sul solco tracciato da Alan Turing nel 1950, con il famoso «test di Turing»2, e aveva per obiettivo quello di riprodurre il funzionamento dell’intelligenza umana su di una macchina.
Mentre la prima IA era simbolica e poteva essere considerata una branca della logica matematica, la nuova IA è connessionista e si può considerare come una parte della statistica. Essa non funziona più sulla deduzione logica ma sull’inferenza e la correlazione statistica (Floridi, 2022, p. 25).
Gli enormi flussi di dati che gli utenti generano collegandosi alla rete per fruire di qualsivoglia servizio, sono diventati la chiave di volta che ha reso possibile l’implementazione di alcune osservazioni di Frederick Jelinek, risalenti agli anni ‘70 del secolo scorso, relative alla presenza di regolarità molto stabili in ogni linguaggio.
I Big Data, sui quali si fonda la moderna IA, non vengono utilizzati così come si presentano, ma sono sottoposti a operazioni di pulitura, standardizzazione e ordinamento, che li sottraggono al contesto singolare delle vite da cui vengono estratti e al loro significato individuale. Qualunque loro ambiguità espressiva viene cancellata in funzione della loro calcolabilità. Questo vuol dire che «il lavoro di produzione dei big data, o piuttosto dei dati grezzi, è dunque un lavoro di soppressione di ogni significato, di modo che questi stessi dati possano essere calcolabili e funzionare non più come segni che significano qualcosa in relazione a ciò che rappresentano, ma come elementi in grado di sostituirsi alla realtà significante, facendola sparire. Così, a quest’ultima subentrano insiemi di reti di dati a-significanti che funzionano come segnali, ossia, che nonostante non abbiano alcun significato, o piuttosto a causa di ciò, divengono calcolabili. In effetti, è proprio questa la definizione di segnale fornita da Umberto Eco: “un segnale è un elemento senza significato, che non significa alcunché, ma che giustamente, proprio perché non ha significato, diviene in tal modo più calcolabile”» (Rouvroy Stiegler, 2016, p. 8).
L’algoritmo è un processo logico-formale, strutturato secondo passaggi logici elementari che conducono a un preciso risultato, in un numero finito di operazioni. Esistono molteplici campi di applicazione degli algoritmi i quali, in società diffusamente informatizzate come le nostre, sono entrati capillarmente nelle nostre vite quotidiane. Esistono algoritmi di ottimizzazione, utilizzati nella finanza e nelle assicurazioni, il cui scopo è massimizzare o minimizzare una funzione (i profitti piuttosto che il rischio). Esistono poi gli algoritmi probabilistici, la cui diffusione è andata crescendo con la disponibilità sempre maggiore di dati, in termini di volume, velocità e varietà (Big Data).
La cattura da parte degli algoritmi dei dati personali ricavati da siti internet, social network e applicazioni per apparecchi elettronici (app), scompone la singolarità degli individui, in sé incomparabile, in particolarità numeriche calcolabili, manipolabili e aggregabili attraverso la ricerca di correlazioni statistiche significative, ovvero di regolarità stabili tra i dati. L’individuo viene reificato attraverso un modello che ne semplifica l’identità, osservandone e misurandone i comportamenti ed estraendone i pattern comportamentali ricorrenti. Ciò che distingue l’approccio statistico da quello classico è che la correlazione non viene più dedotta da leggi fisiche precise ma «astratta» tramite inferenza da un campione di dati. Più numeroso è quest’ultimo, maggiore è la probabilità che le correlazioni statistiche riscontrate sottendano una legge che governa il fenomeno studiato (Ippolita, 2017, p. 29). A partire da questi «calcoli statistici correlazionisti», è possibile creare dei profili digitali individuali, con i quali predire comportamenti futuri, anticipandoli. Il profiling digitale, utilizzato per scopi commerciali, ma anche politici (vedi lo scandalo Cambridge Analytica), proviene culturalmente dal profiling criminale, che utilizzando la psicologia comportamentale, identifica l’autore del reato a partire dal modo in cui è stato commesso. Ma la «governamentalità algoritmica» permette anche di attualizzare la potenzialità, ovvero la virtualità, e «dunque di fare esistere in anticipo degli atti che non sono ancora stati commessi, passando da una logica penale a una logica dell’informazione [renseignement], ed effettivamente la possibilità di disobbedire sparisce completamente, tanto che non è più necessario gestirla» (Rouvroy Stiegler, 2016, p. 16). Cosa farà allora la polizia nel futuribile, se il profilo digitale costruito attraverso la rilevazione automatica dei dati personali equivale a quello di un «sospetto», metterà in atto una carcerazione preventiva come nel film di Steven Spielberg, Minority report? Oggi il predictive policing ci pone già in una situazione simile, con quei suggerimenti che contengono un carattere normativo potenzialmente discriminante e che proprio per questo, per il momento, sono stati abbandonati in alcuni casi: «suggerire dove è probabile che avverranno crimini sulla proprietà significa monitorare particolarmente certe aree e quindi concentrare l’attenzione della polizia su alcune zone, tipicamente, negli Stati Uniti, quelle a larga maggioranza di latini e afroamericani. La polizia di Los Angeles e di molte altre città, però, ha deciso di interromperne l’uso a causa sia delle critiche intorno al suo carattere discriminatorio sia nella difficoltà di provarne l’efficacia nel limitare i crimini» (Miller, 2020 cit. in Numerico, 2023, p. 174). Il pericolo sta nel fare previsioni, in particolare per anticipare comportamenti sociali, psicologici e politici, che non essendo frutto di algoritmi di machine learning descrittivi ma prescrittivi e performativi, possano trasformarsi in profezie che autoavverano (self-fulfilling prophecy).
Per capire come funzionano gli algoritmi «intelligenti» del Web, che stanno al cuore della moderna IA, e che analizzando campioni di nostri comportamenti, fanno previsioni statistiche sulle nostre scelte future e fungono da «agenti di raccomandazione», bisogna ritornare sul cambio di indirizzo che prese la ricerca che si occupava di riconoscitori vocali e di traduzioni automatiche, negli anni ‘80 del secolo scorso. Il primo approccio si fondava sul «paradigma basato sulla conoscenza» (Feigenbaum), seguendo il quale si dovevano implementare modelli e regole grammaticali, con cui discriminare le frasi generate che avevano senso, da quelle che non lo avevano. Le grammatiche che ne risultavano, non erano però mai sufficientemente grandi per gestire le sempre nuove eccezioni che si presentavano. Questo approccio venne abbandonato nel momento in cui si scoprì che utilizzare le regolarità statistiche del linguaggio era molto più efficace: «la tesi che l’intelligenza fosse basata sulla capacità deduttiva attraverso l’uso di regole per la manipolazione di simboli fu destinata a soccombere a causa dell’alto costo computazionale necessario per risolvere con questi metodi anche problemi giocattolo» (Numerico, 2021, p. 130). Il limite in quel momento della nuova prospettiva che si stava affacciando, stava nella necessità di disporre di enormi quantità di dati, con i quali alimentare grandi tabelle le cui celle contenevano le probabilità di ogni parola, allo scopo di addestrare algoritmi che di per sé ignoravano il significato di quelle stesse parole. Questo nuovo approccio implicava fare a meno delle regole teoriche a favore di regolarità statistiche inferite da grandi moli di dati. L’esempio che porta Cristianini per spiegarlo, è quello di un semplice correttore ortografico o suggeritore automatico di parole, che troviamo in tutti gli apparecchi digitali, il quale rileva errori di battitura non perché conosca il significato delle parole o perché incorpori regole grammaticali o di sintassi ma solo perché sostituisce la parola mai vista prima (possibile errore) con parole simili che sono molto frequenti o che sono frequenti in situazioni simili. Questo sistema «non conosce la grammatica né comprende l’argomento del testo: tutto ciò di cui ha bisogno sono informazioni statistiche di tipo generale che possono essere ottenute analizzando un grande corpus di documenti. Tali raccolte di dati contengono almeno decine di migliaia di documenti e milioni di parole» (Cristianini 2023, pp. 29, 30).
Negli anni ‘90 del secolo scorso confluirono assieme metodi statistici in linguaggio matematico per l’estrazione di complesse relazioni da grandi quantità di dati, nuovi metodi per addestrare le reti neurali3 e la creazione del W3 nel 1993. Questo pose le basi della IA moderna, una machine learning, addestrata da enormi quantità di dati, che ne plasmano il comportamento «intelligente», e che si trovano gratuitamente a disposizione nel Web. Oggi le applicazioni più evolute che utilizzano i modelli statistici del linguaggio, funzionano a partire da un miliardo di parole con le quali addestrarli, in quanto essi contengono moltissimi parametri che vanno settati: «oggi le raccomandazioni di Amazon si basano su centinaia di milioni di clienti, quelle di Youtube su due miliardi di utenti, e il modello di linguaggio più avanzato al mondo, con il quale si può instaurare un dialogo e ricevere risposte a domande, – GPT3- ha circa 175 miliardi di parametri, che devono essere appresi analizzando circa 45 terabyte di testo ottenuti da fonti diverse, […] una quantità che richiederebbe oltre 600 anni per essere letta dal più veloce lettore umano (il signor Howard Berg, che appare nel Guinness World Record per essere riuscito a leggere 25.000 parole al minuto» (Cristianini 2023, pp. 51, 66).
Il modo di definire l’intelligenza artificiale come diversamente intelligente rispetto a quella umana, viene declinato da Floridi attraverso quella separazione tra l’agire e l’intelligenza (umana), che è la ragione per la quale l’IA moderna funziona: «l’IA esegue con successo un compito solo se può slegare la sua esecuzione dall’esigenza di essere intelligente nell’eseguirlo» (Floridi, 2022, p.34). Egli afferma questo a partire dalla famosa definizione controfattuale di IA, formulata nel 1955 in occasione del progetto di Darmouth, che pose le basi dei primi studi sull’intelligenza artificiale: «Per il presente scopo il problema dell’intelligenza artificiale è quello di far sì che una macchina agisca con modalità che sarebbero definite intelligenti se un essere umano si comportasse allo stesso modo». In questa definizione non ci si riferisce al pensiero ma al comportamento, ovvero «se un essere umano si comportasse in quel modo, quel comportamento sarebbe definito intelligente. Non significa che la macchina sia intelligente o che addirittura stia pensando» (Floridi, 2022, p. 44).
Se nel settore della scienza cognitiva, l’obiettivo di produrre intelligenza con la IA (IA forte), è stato un fallimento, in quello dell’ingegneria, con la riproduzione di un comportamento intelligente da parte di una macchina non dotata di intelligenza umana (IA debole), è stato invece un successo. La IA riproduttiva sostituisce l’intelligenza umana in molti compiti senza essere “intelligente”, diventando un suo prolungamento, una sua protesi. La tendenza della ricerca nel campo della IA è quella di addestrarla con dati sempre meno storici e sempre più sintetici (artificiali), ovvero dati prodotti da sé medesima (reti neurali autoorganizzanti), ovviando a problemi quali l’inaffidabilità e incompletezza dei dati e la tutela della privacy. AlphaZero, nella sua ultima versione, è riuscito a imparare a giocare a scacchi meglio di qualunque umano, cosa già possibile, e di qualunque software precedente, fondandosi solo sulle regole del gioco, senza alcun bisogno di dati di input esterni. In nove ore si è auto addestrato, giocando e producendo dati sintetici da 44 milioni di partite giocate contro se stesso.
Sembra sempre più evidente come il mondo si vada configurando in un modo che sia compatibile con l’IA e non viceversa. Vengono introdotti sempre più numerosi artefatti logico matematici nei nostri ambienti, in modo tale da re-ontologizzare il mondo in direzione della dimensione dell’infosfera4, quella in cui ormai noi tutti viviamo: «Il mondo sta diventando un’infosfera sempre meglio adattata alle delimitate capacità dell’IA» (Floridi, 2022, p. 55). Stiamo avvolgendo i nostri habitat naturali e sociali in una infosfera digitale, affinché algoritmi e IA, lavorino sempre più in maniera autonoma e automatizzata.
Ma una macchina dotata di IA, se si può considerare intelligente, e si può, considerando l’intelligenza come la capacità di esibire un comportamento efficace in situazioni nuove, non pensa in ogni caso come una mente umana. Essa non deve capire quello che fa, non deve capire il senso di una frase, perché si fonda sulla «irragionevole efficacia dei dati», che nasce dalle correlazioni statistiche tra quest’ultimi. I suoi algoritmi sembrano lavorare senza aver bisogno di una teoria alle spalle: nell’IA i dati hanno preso il posto della teoria. La linea ideologica da cui parte questa considerazione, risale a un articolo di Chris Anderson del 2008, nel quale egli sosteneva che i dati si potevano analizzare senza teoria e questa è «la tesi di fondo che tuttora anima e articola la centralità dei big data, in particolare come soluzione ai problemi di psicologia sociale applicata e sperimentale, oltre che di ogni rappresentazione di abitudini, stati d’animo, desideri e bisogni della popolazione connessa alla rete […] La convinzione di Anderson era che i modelli teorici servivano quando i dati non erano sufficienti a evitarli. I modelli, infatti, sono sempre parziali, limitati, in ultima analisi erronei» (Numerico, 2021, pp. 66, 67).
Viene da chiedersi se quello che si sta compiendo sia un salto epistemico, ovvero un «mutamento di paradigma scientifico», oppure se ci troviamo di fronte a risultati inquadrabili nella «scienza normale», secondo la nota distinzione fatta da Thomas Kuhn (Kuhn, 2009). Stiamo per caso uscendo dall’epoca del principio di causalità per entrare in quella della correlazione? Se così fosse approderemmo a quella che Hegel considerava la forma più bassa di sapere, in quanto priva della necessità della causalità: «la correlazione tra A e B significa: A si verifica spesso insieme a B. Nel caso delle correlazioni non si sa come mai le cose avvengano in un determinato modo. È così e basta. La correlazione mostra una probabilità, non una necessità, e in questo si differenzia dalla relazione causale alla base di una necessità: A provoca B». È solo al livello di un terzo elemento C, il concetto, che si comprende la relazione tra A e B, i quali risultano solo suoi momenti, ma «l’intelligenza artificiale non raggiunge mai il livello concettuale del sapere. Non comprende i risultati che calcola. Il calcolo si distingue dal pensiero in quanto non forma concetti». L’intelligenza dell’IA è macchinica, ovvero si limita a calcolare e a scegliere stocasticamente tra diverse opzioni, rimanendo all’interno dello stesso paradigma, laddove il pensiero, andando incontro all’improbabilità dell’evento, è in grado di operare un salto nel completamente Altro (Han, 2022, pp. 54-56).
Secondo Teresa Numerico, lo scenario più probabile non è quello della sostituzione della teoria con i dati, ma quello dell’occultamento dei modelli teorici che comunque sono presenti e si nascondono nel software e nella modalità di raccolta degli stessi dati che servono all’addestramento degli algoritmi, un’opacità tecnica che nei risultati che produce, può essere fonte di stereotipi e iniquità (Numerico, 2021, pp. 178,179).
La filosofa sottolinea lo statuto ontologico spurio dei dati, i quali non potendo essere utilizzati allo stato grezzo, come già scritto, sono sempre lavorati, ragione per cui non esistono «in purezza […] I dati non sono prodotti direttamente dall’osservazione immediata dei fenomeni, ma sono frutto di una costruzione umana» (Numerico, 2021, p. 77). Questo significa che, nel caso in cui i dati si riferiscano a persone e alle loro attitudini, preferenze, scelte commerciali, politiche, sociali e affettive, le modalità di raccolta e archiviazione dei dati, come la loro natura strutturata o meno, possono veicolare una serie di pregiudizi. In particolare, nelle tecniche artificiali di apprendimento automatico (machine learning), bisogna considerare la presenza di altri elementi soggettivi, che possono diventare fonte di «iniquità, pregiudizi e disparità», quali la discrezionalità dei programmatori nello stabilire i criteri di somiglianza, secondo i quali riconoscere quelle regolarità utili per una previsione attendibile del futuro: «i dati non sono una garanzia di oggettività e la loro messa al lavoro da parte degli algoritmi è condizionata dalle scelte dei programmatori, che intervengono due volte, sia per normalizzarli quando devono essere oggetto di addestramento sia scegliendo i parametri e le caratteristiche che vale la pena mettere in relazione e che sono rilevanti per l’interpretazione delle somiglianze e l’identificazione delle regolarità» (Numerico, 2021, p. 136).
Gli algoritmi di apprendimento automatico, non essendo deterministici ma probabilistici, possono tendere all’apofenia, ovvero riconoscere schemi ricorrenti (patterns) nei dati, che non esistono, semplicemente perché la loro enorme quantità può far rinvenire connessioni che si articolano in molteplici direzioni5 (Boyd, Crawford, 2012, p. 668 in Floridi, 2022, p. 151). Una quantità sempre maggiore di dati, non è sempre garanzia di previsioni precise e accurate, in quanto, come scrive Ruha Benjamin, «la profondità computazionale senza profondità storica o sociologica è soltanto un apprendimento superficiale»6. Le stesse astrazioni in cui consistono i formalismi degli algoritmi, tendono a semplificare la complessità sociale del mondo reale, rischiando anche qui di veicolare all’interno del codice iniquità e parzialità, introdotte a monte dagli sviluppatori che li governano, laddove andrebbe mantenuta una visione più ampia, ancorata al livello della cornice sociotecnica interpretabile, nella quale i dispositivi che li contengono sono inseriti.
Gli algoritmi non sono eticamente neutri, ma quando si pensano tali, si possono fare delle scelte parziali e pregiudiziali. Quando si considerano solo alcune caratteristiche come significative, associando ad esempio alcuni comportamenti frequenti con una particolare zona di una città, si rischia di generare un cluster affetto da discriminazione, la quale può accrescere la ghettizzazione già presente in molti contesti urbani (Numerico, 2021, p. 136). Anche in campo sanitario e del welfare sociale la predittività degli algoritmi di machine learning può generare iniquità nell’assegnazione di cure e nella distribuzione delle risorse. Nel primo caso attraverso un care management, che ha per obiettivo non tanto formulare una previsione più attendibile nell’ambito della prevenzione, quanto quello di poter sostituire, ad esempio nei casi di doppia lettura di un referto diagnostico, la valutazione di un medico con quella di un algoritmo, allo scopo di ottimizzare l’allocazione delle risorse economiche. Questo in mancanza di standard che prevedano alti livelli di follow up sui dati per la validazione. Nel secondo caso, lo stesso digital welfare state, ovvero la tendenza ad affidarsi agli algoritmi per valutare lo stato di bisogno delle persone disagiate e per approntare interventi di sostegno al reddito, tende a creare delle digital poorhouse (Eubanks, 2018 in Numerico, 2021, p. 200), ovvero degli steccati all’interno dei quali si viene identificati, controllati, profilati e puniti e dai quali risulta difficile uscire e dove il rilevamento di relazioni e correlazioni tra i dati (pattern recognition) offre il sostegno teorico a politiche competitive, estrattive e discriminatorie nei confronti delle soggettività più fragili.
Quello che è sempre molto chiaro per Numerico è che sono i programmatori a fissare le regole delle procedure algoritmiche che categorizzano e governano le persone. Non si tratta quindi del dominio della tecnica in sé, ma di chi detiene il potere di utilizzarla come strumento di quella «governamentalità algoritmica» di cui parla la Rouvroy. Come risulta da alcune ricerche, questi programmatori sono generalmente bianchi, altamente qualificati e provenienti da classi sociali medio alte. Questo comporta, giocoforza, che siano portatori di determinati valori, che saranno veicolati nelle modalità di ricerca e nella qualità dei dati, e nelle opzioni di scelta contenute nei software che svilupperanno, portando con sé alcuni pregiudizi, causa di bias e discriminazioni, consapevoli o meno che ne siano. L’IA e gli algoritmi su cui si fonda sono dispositivi sociotecnici, che vengono gestiti da sviluppatori umani, che li progettano e li implementano, fornendo loro una ideologia e una direzione che sono contenuti nel loro codice. Come sono esseri umani anche quelli che generano, raccolgono ed etichettano le informazioni che entrano nei data set di input con i quali addestrare l’IA e che possono portare con sé stereotipi e pregiudizi. Un articolo del Guardian spiega come l’IA, sia affetta da numerosi pregiudizi di genere, che portano con sé, ad esempio, l’oggettivazione del corpo delle donne, quando le immagini che le ritraggono, sono valutate come sessualmente più provocanti, anche quando non lo sono (donne in costume o in gravidanza), rispetto a quelle degli uomini7.
Tra i pregiudizi, ne esiste uno che può alimentare previsioni inconcludenti, piuttosto che disabilitare e deresponsabilizzare chi deve prendere decisioni, ovvero quello per cui le analisi computerizzate, forniscono maggiori garanzie di oggettività, rispetto alle valutazioni fondate sull’esperienza personale. In particolare, l’intelligenza artificiale conversazionale assume uno statuto oracolare e, più in generale, il digitale quello di depositario della verità in quanto, come scrive Éric Sadin, quest’ultimo «si erge a potenza aletheica, un’istanza destinata a mostrare l’aletheia, la verità, nel senso definito dalla filosofia greca antica, inteso come lo svelamento, la manifestazione della realtà dei fenomeni al di là della loro apparenza» (Sadin, 2019, p. 9). Verità algoritmica è però un ossimoro, in quanto, affinché si dia verità, è necessario pensare, e l’IA non pensa, ma come qualunque altra macchina informatica, calcola solamente. Un calcolo, quello operato dall’algoritmo, nei cui risultati possono convivere assieme il vero e il falso, non dal punto di vista logico formale, ma da quello fattuale, nel senso che alcune volte l’esito dell’elaborazione, non ha alcuna corrispondenza nella realtà.
Gli algoritmi complessi, in particolar modo quelli relativi al machine learning, presentano anche altri problemi di opacità, che tendono a farne delle vere e proprie black boxes. Tra i fattori che contribuiscono alla mancanza di trasparenza algoritmica, ci sono i limiti cognitivi umani, che non permettono di interpretare giganteschi sistemi di algoritmi, che elaborano enormi quantità di dati. Le stesse grandi dimensioni del codice, la possibilità che hanno gli algoritmi di essere riprogrammati in continuazione e distribuiti su reti di macchine, all’interno di strutture sociotecniche che tendono a ibridare agenti umani e artificiali, rendono difficile anche individuare la catena delle responsabilità delle loro azioni. Non c’è trasparenza negli algoritmi di autoapprendimento, in quanto essi «alterano la loro logica decisionale (producono nuovi insiemi di regole) durante il processo di apprendimento, rendendo difficile per gli sviluppatori mantenere una comprensione dettagliata del motivo per cui sono state apportate alcune modifiche specifiche» (Floridi, 2022, p. 154).
Esistono algoritmi in grado di calcolare non solo una regressione lineare dei dati, ovvero una loro correlazione diretta, a partire da una dipendenza immediata tra i dati in ingresso e una proiezione futura dei cambiamenti oggetto di analisi, ma anche relazioni non lineari. Per queste ultime, che sono quelle in grado di fornire le soluzioni più originali, in quanto rilevano correlazioni tra i dati impreviste, sono necessarie reti neurali multistrato adatte al deep learning (vedi nota 9). In questo caso l’algoritmo viene addestrato con tecniche diverse, come ad esempio l’«apprendimento per rinforzo», ovvero un metodo trial and error che ricompensa le mosse corrette. Il peso dei neuroni artificiali viene modificato a seconda del livello di errore dei risultati. Quando la rete neurale è complessa e strutturata con molteplici strati, l’addestramento degli strati più profondi risulta di difficile comprensione. Questo comporta l’impossibilità di dare una spiegazione esaustiva del funzionamento dell’algoritmo, lasciando un alone di opacità sul suo modo di operare. Se l’apprendimento profondo si è dimostrato efficace nei videogiochi e, tra le tante applicazioni, nel riconoscimento facciale, non si può dire altrettanto nel caso dell’essere umano. La causa è legata al fatto che se in un videogioco si sa esattamente quale sia il risultato che si vuole ottenere, nel caso degli esseri umani questo non è sempre vero. L’essere umano spesso non sa quello che vuole; la sua ambivalenza, come l’ambiguità che il suo linguaggio nasconde e la dimensione inconscia, non sono declinabili nei termini dell’algebra di Boole, per cui risulta difficile comprendere automaticamente quale sia il suo obiettivo. La stessa trama dell’esistenza individuale nel mondo reale, presenta una serie di casualità, cancellazioni e occultamenti dei quali un’intelligenza artificiale non potrebbe dar conto.
Byung-Chul Han, nella sua critica rivolta all’IA partendo da categorie heideggeriane, afferma che il pensiero umano in profondità ha una natura analogica, che si dà a partire dall’affetto che scaturisce dal preliminare coinvolgimento nel mondo, che precede il pensiero stesso. A dire che il mondo si apre al pensiero, dal momento in cui il mondo stesso, suscitando uno stato d’animo fondamentale, rende possibile la comparsa del pensiero. A partire da questo, egli sostiene che l’intelligenza artificiale non può pensare, ma solo calcolare, in quando le manca la dimensione affettiva. E non pensa anche perché, se lo stato d’animo fondamentale al fondo del pensiero, è quella commozione aurorale che lo spinge fuori di sé, aprendo il mondo alla sua comprensione, l’intelligenza artificiale digitale, priva com’è di spessore corporeo affettivo e analogico, non può essere fuori di sé, risultando perciò priva di mondo: «il pathos è l’inizio del pensiero. L’intelligenza artificiale è apatica, vale a dire senza pathos, senza passione. Essa calcola» (Han, Le non cose, 2022, p. 52).
Come scrive Franco Berardi, l’intelligenza generativa artificiale è in grado di riconoscere il quadro sintattico di un’espressione, ma non quello semantico e pragmatico, quello del «vivente intensivo nel processo di comunicazione, perché questa capacità dipende dall’esperienza di un corpo, e questa esperienza non è alla portata di un cervello senza organi, quale è ogni intelligenza artificiale. Gli organi sensibili costituiscono una fonte di conoscenza contestuale e autoriflessiva di cui l’automa non dispone»8. Per non parlare della parte emozionale dell’essere umano, come riverbero della psiche nel soma, «per la quale le emozioni possono coglierci prima ancora che noi si sia consapevoli del loro insorgere […] Una mente emozionale che è assai più rapida di quella razionale (l’unica simulabile da un IA), perché passa all’azione senza neppure fermarsi un attimo a riflettere sul da farsi» (Goleman, 2015, pp. 336, 337).
L’esperienza propriamente umana si dà infatti impegnando un corpo nella sua complessità e nella sua articolazione spazio motoria. Il suo tendenziale esonero, dovuto all’uso delle tecnologie digitali, porta con sé un’esperienza disincarnata, che si risolve in una non-esperienza, facile preda del controllo del panottico digitale e di dissimulate catture immaginarie.
Nel 2023 è balzata alla ribalta della pubblica opinione una particolare forma di IA, quella conversazionale generativa di ChatGPT (Generative Pretrained Transformer9), un modello di elaborazione del linguaggio, implementato da un potente algoritmo di apprendimento automatico, che attraverso un chatbot10, può interloquire con chiunque, utilizzando il linguaggio naturale. L’ultima versione della famiglia di intelligenze artificiali GPT, GPT-4, è in grado di rispondere a qualunque domanda in qualunque lingua, sintetizzare centinaia di pagine di un libro, scrivere codice informatico come pure comporre poesie, fare le più varie previsioni. L’IA Midjourney, a sua volta è in grado di creare immagini da descrizioni testuali, che risultano identiche a quelle di soggetti reali. È in fase di test, ma verrà rilasciata a breve, Sora, l’ultima creatura di OpenAI, una IA in grado di creare video con ottima definizione e videorealismo, a partire da una richiesta testuale. Con questa IA è anche possibile creare video a partire da un’immagine o da alcuni fotogrammi, con tutti i pericoli di deepfake e disinformazione. Ma Sora dimostra anche di conoscere la grammatica cinematografica e di poter creare film con un certo stile narrativo. L’utilizzo di queste nuove tecniche di IA assieme alla proliferazione di agenti artificiali come i bot11, sempre più indistinguibili dalle persone, elevano esponenzialmente il rischio che nei nostri canali informativi vengano veicolate false informazioni che non possono essere distinte da quelle veicolate da comunicazioni umane.
In un mondo in cui le grandi narrazioni sono ormai relitti del passato, in cui anche le scienze dure hanno abbandonato non solo ogni pretesa di verità, ma anche di oggettività, dopo la scoperta della meccanica quantistica, il performativo sistema dei media fa essere qualcosa nel momento in cui lo fa apparire e la pletora valoriale e contenutistica è ancora assorbita dalla livella postmoderna, la possibilità di creare testi, immagini e filmati tramite IA, indistinguibili da quelle che hanno un referente reale, tende a erodere sempre più la cornice simbolica della realtà condivisa, nella direzione di infinite eterotopie immaginarie. Il rischio di una Babele individuale, sociale e globale, ovvero di un dis-orientante caos generalizzato, è quello di condurre a svolte politiche che, per mettere ordine in questo caos, impongano una svolta autoritaria.
In merito alla neutralità della tecnologia in generale, e quindi anche di quella digitale, David Noble, negli anni ‘90, sottolineava che in ogni uso della tecnologia è inscritta una relazione di potere. Si potrebbe aggiungere, in merito ai dispositivi digitali, che molti di questi non sono strumenti neutri in sé, in quanto concepiti, realizzati e diffusi allo scopo di rivoluzionare le strutture relazionali e lavorative, nella direzione di un’estrazione di valore, il più veloce possibile, da ogni aspetto della vita.
La distinzione fondamentale da fare è quella tra tecnica e tecnologia, proposta da Roberto Finelli nel suo Filosofia e tecnologia, recuperando la particolare accezione riservata da Marx al termine tecnologia. Questa accezione torna utile a Finelli per evidenziare il carattere eminentemente astratto che qualunque lavoro assume, quindi anche quello digitale, una volta sussunto dalla logica riproduttiva del capitalismo. La tecnologia moderna, infatti, come sottolinea il filosofo, non è neutra, ma riunisce in sé l’applicazione della scienza con il comando eterodiretto e normato sul lavoro, assimilato a cosa tra cose, in funzione dell’intensificazione della produttività, laddove i rapporti sociali intrinseci a essa e asimmetrici, rimangono occultati. Scrive Michéa: «le tecnologie moderne pongono un problema perché interiorizzano nella loro stessa concezione determinati rapporti sociali, concetti intellettuali, maniere di produrre e di vivere» (Michéa, 2018, pos. 2259). La tecnologia moderna trasforma corpi, menti e natura, modellandoli secondo quei fini che appartengono alla dimensione sovradeterminante dell’accumulazione di capitale. L’astrazione del lavoro risulta omologa alla fondamentale astrazione del capitale, come «coerenza tra astrazione e impersonalità della funzione umana e astrazione e impersonalità della ricchezza capitalistica da produrre» (Finelli, 2022, p. 93). Con la differenza che mentre il fordismo irregimentava i corpi rimuovendone la mente, il capitalismo digitale fa l’operazione opposta, costringendo al lavoro una mente, che avendo tagliato i ponti con la propria corporeità, risulta una mente astratta.
3. Lavoro, ambiente e conflitti armati nell’epoca dell’intelligenza artificiale.
Negli anni ‘90, l’evoluzione delle tecnologie informatiche, aveva portato con sé una nuova narrazione, che annunciava un futuro ormai prossimo, in cui si sarebbe lavorato di meno, con meno fatica e più tempo libero, in un regime economico di crescita illimitata. Una narrazione che ripeteva pari pari un ritornello già ascoltato nelle promesse delle “rivoluzioni” tecnologiche precedenti a questa. Sappiamo tutti, per esperienza, com’è andata: «è da mezzo secolo che la qualità del lavoro sta peggiorando sempre più, sempre nella applicazione di quella razionalità strumentale/calcolante-industriale che cerca con ogni mezzo di accrescere la produttività e il pluslavoro per accrescere il profitto privato; e questo mediante flessibilizzazione e precarizzazione del lavoro, esternalizzazione e remotizzazione dell’organizzazione industriale, piattaformizzazione come nuova forma della fabbrica – cioè grazie all’egemonia dell’ideologia neoliberale, ma soprattutto grazie alle nuove tecnologie e alla digitalizzazione del vecchio taylorismo che esse permettono di realizzare»12.
Nel presente, il lato feticisticamente oscuro della IA, aldilà delle proiezioni distopiche che prevedono intelligenze artificiali fuori controllo, che andranno a sostituire oltre che il lavoro (cosa auspicabile nel caso si tratti di un mero impiego), anche gli stessi esseri umani, è quello in cui la forza lavoro rimane il lato occulto del capitalismo digitale. Quello nel quale le attività di data work, come prelevamento e scrematura dei dati, programmazione dei transformer che li organizzano e rinforzi per migliorare l’apprendimento degli algoritmi, tramite feedback umani, vengono spesso svolte da lavoratori del Sud globale, sfruttati economicamente e defraudati del loro surplus cognitivo, quello incorporato nelle macchine che essi addestrano per migliorarne le prestazioni. Insomma, anche la tecnologia della IA, e non poteva essere altrimenti, vista la sua sussunzione alla logica proprietaria e di sfruttamento capitalistica, concentra in sé, dalla produzione al consumo, un sistema di relazioni sociali e di potere asimmetriche. Quando non sia già in sé, a partire dal suo concepimento, lo strumento più potente e raffinato, escogitato dal sistema produttivo capitalistico, per continuare a riprodursi.
Se la stima fatta da OpenIA, società produttrice di GPT-4, di una trasformazione o sostituzione dell’80% dei posti di lavoro che saranno interessati nel prossimo futuro dall’IA, la realtà del presente è la sostituzione di posti di lavoro inquadrati, con micro-lavori iper-precari, distribuiti in particolar modo nel Sud del pianeta. Antonio Casilli, autore di Schiavi del clic, scrive: «Alla domanda: “Dove viene prodotta l’intelligenza artificiale?”, oggi noi diamo una risposta originale: non nella Silicon Valley o in grandi centri tecnologici dei paesi del Nord. I dati, ingredienti fondamentali dell’IA, vengono prodotti nei paesi emergenti e in via di sviluppo. Foto, video e testi sono filtrati e arricchiti dai lavoratori delle piattaforme internazionali come la famigerata Mechanical Turk di Amazon, che li paga a cottimo per realizzare piccoli progetti online che durano appena qualche minuto: trascrivere, registrare, taggare, moderare, ecc. Ci sono anche altre grandi imprese quasi sconosciute come Appen o Telus, e piattaforme più piccole come la russa 2captcha e l’africana Sama. Nel gennaio scorso, Sama è stata oggetto di rivelazioni da parte della rivista Time, la quale ha scoperto che centinaia dei suoi micro-lavoratori in Kenya hanno “addestrato” ChatGpt […] La mappa globale che emerge dalle nostre ricerche attesta la costituzione di un vero e proprio esercito industriale composto principalmente da persone tra i 20 e i 30 anni (ma anche quarantenni e pensionati nei paesi del Nord). In alcuni paesi, la maggioranza è costituita da donne con figli a carico che accettano di essere pagate meno di due euro all’ora. Anche nel Sud globale, questi salari non sono sufficienti per una vita dignitosa. Il fenomeno è strettamente legato alla disoccupazione e all’economia informale. I micro-lavoratori hanno regolarmente un livello di istruzione superiore alla media del loro paese, ma non riescono ad accedere al mercato del lavoro e guadagnano realizzando «micro-task», ovvero brevi progetti retribuiti pochi centesimi»13.
In merito alle emissioni climalteranti dell’IA, queste dipendono dalla potenza dell’hardware utilizzato, dalla quantità di CO2 emessa dalla fonte energetica che lo alimenta e dall’energia richiesta dall’addestramento dell’algoritmo. Si pensi che una sola sessione di addestramento di GPT-3 produce 223.920 chilogrammi di CO2 che corrispondono, se un’automobile americana in media emette all’incirca 4600 chili di CO2 all’anno, a quanto emesso da 49 autovetture in questo arco di tempo e che per il raffreddamento delle macchine si utilizzano 700.000 litri d’acqua. Si consideri inoltre che dal 2012, da quando cioè il deep learning è diventato centrale per l’IA, la potenza di calcolo richiesta per addestrare tale modello, è cresciuta esponenzialmente, assieme alla richiesta di energia e alle relative emissioni di CO2. La domanda di data center, indispensabili per il settore ICT (Information and Comunication Technology) e per l’IA in particolare, continua a crescere, e l’energia per alimentarli, che nel 2022 corrispondeva all’1% della domanda globale di elettricità, secondo la Commissione europea, aumenterà del 28% entro il 2030. Nonostante l’IA giochi un ruolo importante nelle previsioni sul cambiamento climatico e sebbene si stia cercando di sviluppare hardware e software più efficienti, essa consuma quantità crescenti di energia che generano crescenti emissioni di gas serra, sia nella fase di addestramento dei modelli che del loro utilizzo. Attualmente all’IA è attribuibile una parte dell’1,4% delle emissioni globali di CO2 dovute alle ICT, le quali però nello scenario peggiore, potrebbero crescere fino al 23% entro il 2030 (Floridi, 2022).
Anche il modo di condurre i conflitti armati, sta mutando nella direzione di un sempre maggior utilizzo della tecnologia digitale e dell’IA negli armamenti14. La guerra in Ucraina è diventata un laboratorio di sperimentazione del machine learning nel settore militare. Per il momento le armi autonome che vengono utilizzate, come i droni, sono comunque soggette alla supervisione umana, ma in futuro si potrebbero utilizzare anche armi autonome intelligenti, che non richiedono alcun intervento umano per selezionare l’obiettivo e sparare. L’utilizzo degli algoritmi è molto diffuso, come il sistema GIS Arta, in dotazione a Kiev, che associa a ogni obiettivo russo, l’unità di artiglieria che si trova nella posizione migliore per colpirlo. Oppure sistemi di riconoscimento vocale AI per elaborare velocemente le comunicazioni dell’avversario intercettato, estraendo quelle che risultano sensibili per il conflitto in corso. Le foto accessibili sui social media e rilevanti dal punto di vista geo-militare, assieme alle riprese dei droni, addestrano IA che permettono di identificare carri armati nemici mimetizzati, distruggendoli in tempo quasi reale, e che stanno diventando sempre più autonome nell’assumere decisioni. Una cyberguerra, quella in corso, in cui svolgono anche un ruolo determinante gli hackers, con circa 200 attacchi informatici al giorno da parte della Russia. La tendenza è verso lo sviluppo di una rete di “uccisioni” che colleghi in tempo reale armi, soldati e comandanti, creando un automa bellico automatizzato ibrido e coordinato in tutte le sue parti, umane e non. Se le guerre del futuro saranno sempre più combattute da ibridi uomo macchina e da macchine autonome connessi in rete, i rischi saranno quelli di scatenare conflitti ubiquitari, pilotati da hacker o ad opera di entità anonime.
La delega all’IA di un numero sempre maggiore di decisioni sul campo, condizionata anche da quella AI overreliance o “fiducia cieca” che gli esseri umani attribuiscono spesso al calcolo automatico e alla logica algoritmica di quest’ultimo, che tende in molti casi all’ottimizzazione matematica, ovvero a un calcolo che non contempla alcuna opzione etica o eccezione, il pericolo di “danni collaterali”, piuttosto che di situazioni che sfuggano al controllo umano, può diventare molto alto.
4. Disautomatizzare e ripoliticizzare il desiderio. Per un’estetica desiderante.
Come spiega Stiegler, a partire dalla rivoluzione industriale lo sviluppo tecnologico si è sempre trovato in anticipo rispetto alla sua regolamentazione in uno stato di diritto. Gli stati di fatto, non ancora normati, emersi con le innovazioni tecnologiche, hanno generato shock, destabilizzazioni sociali e rendite di posizione. L’infrastruttura reticolare del Web, comparsa nel 1993, ha subito nel tempo un regressivo processo di enclosures dello spazio virtuale da parte delle multinazionali che hanno creato dispositivi software, le cui conseguenze sono state dipendenza, controllo e sfruttamento.
L’analisi e l’utilizzo dei Big Data è in mano a pochi gruppi di potere, di tipo industriale e militare. Si pone quindi il problema di un controllo e di una verifica delle inferenze operate al di fuori del metodo scientifico e in mancanza di teorie esplicite: «al momento i big data assomigliano più a un oracolo pseudo-scientifico a cui affidarsi per evitare di formulare una teoria, per sottrarsi alla presa di posizione. Invece di formulare ipotesi e cercare di verificarle in maniera empirica, gli apprendisti stregoni dei big data commerciali suggeriscono ai decisori politici, militari e ai comuni cittadini che non c’è bisogno di alcuna riflessione, non è il caso di preoccuparsi del quadro generale, non è necessaria alcuna dialettica democratica perché i dati parlano da sé, basta saperli interrogare e ascoltare. Una pericolosa deriva, una delega del tutto fideistica in linea con i principi della tecnocrazia» (Ippolita, 2017, p. 31).
L’ideologia dei Big Data, secondo la quale tutto è prevedibile, viene smentita da quelli che Rouvroy chiama resti, ovvero quelle effettualità che non si sono realizzate, quelle potenze che non sono passate all’atto, quel virtuale che non è diventato attuale, quelle possibilità che non sono prevedibili, quelle utopie rimaste tali, tutte dimensioni non digitalizzabili, perché non attualizzatesi, le quali lasciano aperta quella condizionalità, che eludendo ogni previsione, custodisce la libertà di ciascuno. In questo senso la virtualità è quella dimensione del soggetto che fa si che «la nostra individualità non sia mai contenuta del tutto dall’attualità. Siamo abitati dai nostri sogni, dal nostro passato, abitati anche dal nostro futuro, dalle proiezioni che facciamo, ciò che immaginiamo attorno a noi» (Rouvroy, 2016, p. 15). Siamo esseri stratificati, abitati da logiche diverse, quella diurna del nostro pensiero razionale e dell’ombra del pre-conscio che digrada in quella rimossa e sepolta nell’oscurità dell’inconscio, sotto il segno dell’ambivalenza e della polisemia. Il nostro passato si è iscritto su tracce che spesso condizionano il nostro futuro facendone un destino. Ciò che ci viene incontro è «quello che ha da venire» (Jung, 2010), in quanto lo fa nelle modalità anticipate e predisposte dalle nostre proiezioni, quindi secondo un tempo che è quello del futuro anteriore. Attraverso una soggettivazione del passato che ne fa non un destino deterministico e necessitante ma un destino scelto, ovvero sottratto a una ripetizione più forte di noi e che non governiamo, per diventare un progetto consapevole di futuro che si nutre di un passato rivisitato attraverso una trama generativa di senso.
Tutte dimensioni queste, precipuamente umane, non accessibili da quello che è stato definito inconscio digitale, frutto dell’estrazione di dati operata dall’IA15.
La «governamentalità algoritmica» attualizza invece il virtuale, ovvero «fa esistere in anticipo ciò che non esiste che su di una modalità virtuale, separando gli individui dalla possibilità di non fare sempre ciò di cui sono capaci, o di non subire sempre tutto ciò che sono suscettibili di subire». Secondo Rouvroy si tratta di proteggere la «possibilità di non essere assimilati alla somma delle nostre potenzialità (attualizzate), dunque di non essere giudicati in anticipo per il fatto che si ha un profilo un po’ come quello o un po’ come quell’altro, di non subire nell’attualità della propria vita le conseguenze di questi profilaggi», come potrebbe accadere con i premi assicurativi di una polizza vita, modulati su profili di rischio individuali psicometrici, costruiti con dati estratti da social network, mailing lists, ecc. (Rouvroy, 2016, pp. 11,12)
Ci si deve prendere cura dell’imprevedibilità dell’avvenire, dell’incidente del futuro, per scongiurare un divenire probabilistico, che annulli le possibilità inedite di biforcazione della struttura rizomatica del divenire dell’essere delle cose e il farsi di un evento, nella ripetizione di previsioni che pre-vedendo, pre-determinano ogni accadimento. Gli algoritmi si fondano sull’assunto che il futuro sarà tendenzialmente uguale a quel passato cui appartengono i dati sui quali si addestrano e che i limiti delle loro previsioni potranno essere superati quando disporranno di una mole di dati sufficiente. In questo senso si comprende perché alcuni ricercatori di Google, li abbiano definiti con l’efficace espressione di «pappagalli stocastici»16: essi ripetono a memoria rimasticandole, ricombinandole e riorganizzandole, le informazioni con le quali sono stati addestrati, inferendo e predicendo stocasticamente situazioni generali e/o future.
Numerico ritiene che sia «cruciale definire una strategia epistemologica e politica insieme, che ci permetta di fornire giustificazioni per i giudizi che sono il frutto dell’azione algoritmica sui dati. Tale strategia consentirebbe il riconoscimento del carattere comunque politico di ogni assetto algoritmico che riguardi l’anticipazione dell’agire sociale in diversi campi» (Numerico, 2023, p.181).
Utilizzando il lessico e l’apparato concettuale di Bernard Stiegler, potremmo scrivere che quello che bisogna evitare è la cattura anticipata delle protensioni, ovvero delle aspettative di futuro individuale e collettivo, intese come attese che proiettano in avanti l’oggetto desiderato. Cattura che si realizza attraverso «il calcolo intensivo che si basa su dati massivi, dove il trattamento dei dati, che sono le ritenzioni terziarie17 digitali, si produce in tempo reale (alla velocità della luce), su scale globali di parecchie centinaia di miliardi di dati, e attraverso dei dispositivi di cattura installati nell’intero pianeta praticamente in tutti i dispositivi relazionali che formano una società (ATM, smartphone, RIFD ecc.) e le stesse ritenzioni terziarie digitali e gli algoritmi che permettono sia di produrre i dati che di sfruttarli, rendendo possibile il cortocircuito della ragione come facoltà sintetica, che si ritrova quindi accelerata a causa di un intelletto divenuto una facoltà analitica automatizzata». Cattura che trasforma progressivamente le ritenzioni secondarie in un circuito chiuso che sigilla ogni possibile apertura delle protensioni verso il futuro.
In ultima istanza, la vera posta in palio nell’epoca iperindustriale è estetica, termine quest’ultimo da intendere nel senso più ampio di sensazione, sensibilità (aisthésis). Sensibilità, che «non è semplicemente psichica o psicosomatica, ma è immediatamente e originariamente sociale perché costituita dal simbolico» (Stiegler, 2019, pp. 81-84). Una sensibilità che oggi, condizionata, eterodiretta e modellata com’è da stimoli preconfezionati ad arte, alimenta un Sé, costruito dietro le quinte del settore del marketing digitale, che risulta essere un falso e funzionale al mercato, Sé.
Sia Stiegler che Berardi, sulla scia di Bateson, infatti, indicano nella dimensione estetica, quella che contiene qualunque cosa appartenga alla sfera della sensibilità, l’unica via per uscire dall’irregimentazione di corpi e menti ad opera del Leviatano digitale globale. Scrive Stiegler che «la questione politica più importante, e forse la sola, se mai ancora una questione può essere politica, è quella dell’estetica del noi; nell’epoca dello sfruttamento industriale dei tempi di coscienza e dello spirito che essi costituiscono, epoca della mancanza d’epoca, come se noi mancassimo di noi…» (Stiegler, 2021, I, p. 78).
Diventa fondamentale una nuova «condivisione del sensibile», da costruire all’interno della società, nella quale la figura degradata del consumatore di suoni e immagini, si trasformi in quella del cultore, che crede negli oggetti che ama. Nel caso dell’arte, infatti, si tratta sempre di credenza, quella in una finzione che risulta necessaria alla vita, nella sua immanenza e trascendenza (Stiegler, 2021, II, 128, corsivo mio).
Per opporsi alla perdita di partecipazione estetica dell’individuo, a quella che il filosofo francese chiama «proletarizzazione generalizzata», indotta dal marketing che alimenta la società dell’iperconsumo, è necessario un allargamento dell’arte nella direzione dell’individuazione psicosociale, in quanto è «la necessità stessa dell’arte, che sola può legare il selvaggio pulsionale da cui procede, sotto forma di un desiderio che lo sublima e lo costituisce in philia, con l’intermediario delle opere» (Stiegler, 2021, II, 145), prodotte come processo sociale. Si tratta di instaurare nuovi concetti e pratiche artistiche per modellare una scultura sociale che fondandosi su di una memoria preindividuale condivisa e viva, inauguri una «nuova epoca del sensibile». Affinché queste pratiche vivifichino la memoria, rendendo possibile l’individuazione psicosociale, è però necessario l’esercizio e la ripetizione. Condizioni, queste ultime, necessarie a creare quella differenza della singolarità nel sensibile, come condizione di ogni individuazione psichica e sociale. Perché si dia pratica è però necessario tempo, quello dell’otium e non del negotium, quello del quale l’individuo viene costantemente defraudato. Tempo dell’otium nel quale modellare il proprio Sé, a partire da quella scultura sociale frutto di una memoria, che se non rinnovata, tende all’oblio. Ciò che risulta necessario è «inventare i circuiti di una nuova economia libidinale», che agganciando il desiderio alla con-sistenza dell’oggetto e non all’in-sistenza del segnale, apra all’imprevedibilità del futuro (Stiegler, 2021, II, 154).
Solo perseguendo l’equilibrio tra immaginazione, come facoltà di dare una direzione al futuro, e intelletto disautomatizzato, come funzione ricondotta nel più ampio alveo della ragione ermeneutica, quella che interpretando il contesto, apre all’improbabile della singolarità e non alla ripetizione seriale di ciò che è già stato, potremo alimentare un’estetica che sappia instaurare un rapporto creativo e molteplice con l’esterno. Ricordando sempre che i dispositivi artificiali dei quali ci siamo circondati, e ai quali molti attribuiscono intelligenza e autonomia, non sono entità che si sono sviluppate per partogenesi, ma sono sempre il prodotto di quella intelligenza collettiva (general intellect), concettualizzata a suo tempo da Marx. In essi si coagulano il lavoro e l’intelligenza sociali, che ne hanno permesso la progettazione e la costruzione, perciò sono «soggetti collettivi intessuti di attività umane: dalla produzione dei dati, alla loro scrematura, dalla programmazione dei transformers che organizzano i dati, alle attività di apprendimento per rinforzo, con il feedback umano»18.
Sul piano della strategia politica antagonista del macchinismo digitale sotto comando capitalista, oltre a forme di luddismo 4.0 e di ripresa del controllo delle infrastrutture tecnologiche nella direzione di un socialismo digitale che ne consenta un uso alternativo, il collettivo Into the Black Box aggiunge «percorsi e potenzialità che si aprono sul piano delle forme di soggettivazione di tipo antagonista che configurano quella che in via preliminare potremmo definire una “(contro)soggettività algoritmica” di rottura. L’algoritmo, infatti, se considerato non come un semplice artificio matematico o un oggetto autonomo, ma come la configurazione dinamica di forze sociali che lo plasmano, non si definisce come un’astrazione tecnica, ma come un risultato sociotecnico dell’intelligenza collettiva. Piuttosto, esso emana una soggettività “fisica” ben oltre sé stesso, interagendo e mutando di continuo a partire dalle interazioni sociali che costruisce e nelle quali è inserito (Into the black box, 2021, p. 36). Avviandoci in una direzione di ecologizzazione di queste interazioni, in chiave “decrescente”, questo significherebbe concepire e implementare modelli le cui regole di funzionamento non abbiano come obiettivo l’accumulo quantitativo senza limiti della produzione o lo stilare graduatorie e assegnare punteggi in modo da aumentare la competizione globale, ma il miglioramento della qualità e della gestione di quello che viene prodotto, su di un piano redistributivo di equità sociale, economica e ambientale. Con algoritmi la cui predittività, generata da Big Data totalmente anonimi e sottoposti a rigidi controlli anti bias, sia al servizio della presa di decisione su cosa, come e quanto produrre quello che serve a condurre la vita sul pianeta, nella tutela di tutte le sue forme, in un’ottica neghentropica.
L’ecosistema algoritmico, che avvolge la nostra vita, monitorando i nostri comportamenti e modellando le nostre scelte, con il suo sistema di raccomandazioni, condizionamenti e dissimulati ordini eterodiretti, e il suo potere predittivo, va indirizzato verso lo sviluppo di una maggiore autonomia umana, piuttosto che il suo contrario, come avviene ora. In caso contrario l’autodeterminazione e la dignità dell’essere umano rimarranno un pallido ricordo. Floridi suggerisce «come metodo di ricerca e innovazione responsabile, il “design partecipativo”», attraverso il quale negoziare interessi e desiderata delle parti umane coinvolte dai sistemi algoritmici, prima della loro implementazione, in vista di un «contratto sociale algoritmico» (Floridi, 2022, p.168). Una sorta di audit pubblico, che raccolga e armonizzi le istanze di tutte le parti coinvolte e sottomesse al modus operandi degli algoritmi e al soft power di cui quest’ultimi sono spesso le leve. Agendo allo stesso tempo una conflittualità dal basso fisica e virtuale, per le strade delle città e in quelle del web, in vista di una disautomatizzazione del golem cognitivo globale, che lo riplasmi in funzione di servizi orientati alla cura del Sé, del Noi e della Vita in ogni sua forma.
Conclusioni.
Quello che risulta improrogabile e necessario, è ridare centralità al tema della soggettività umana, in modo tale che la rivoluzione tecnologica digitale e segnatamente l’intelligenza artificiale, non siano guidate da processi autonomi senza soggetto e, sottoposte all’imperativo accumulativo capitalistico, siano amplificatori di entropia, come oggi avviene, ma dall’attribuzione di significato da parte di una mente che, radicandosi nella corporeità nella quale si trova incarnata, si proietti nell’intenzionalità di una coscienza, in grado di indicare una direzione neghentropica al nostro futuro. Affinché questa direzione possa essere percorsa, è necessario un Ego che non sia il riflesso speculare (moi) di una IA generativa conversazionale come ChatGpt la quale, modificando i suoi parametri in funzione dei feedback che le vengono ritornati dalle risposte che ci fornisce, tende sempre più ad assecondarci. Quello che serve è un Ego (je) che fondandosi sulla collettività simbolica nel cui seno esso nasce, sappia declinarla nell’unicum della sua individuazione singolare.
Nella consapevolezza che i prodotti di ICT, se continueranno a creare doppi statistici digitali e ad automatizzare le esistenze, non potranno mai restituirci quella possibilità di sognare, che sta al fondo di ogni pensiero umano. E che solo se consentiranno forme di soggettivazione psicosociale in grado di ri-orientare l’economia libidinale, ora investita nel circuito chiuso dello speculum digitale, nella direzione di una riorganizzazione del sensibile che apra ai molti che abitano dentro e fuori di noi, potremmo dire che saranno stati messi al servizio dell’autonomizzazione del singolo e della sua convivenza con gli altri, nella diversità della molteplicità. Secondo un modello antropologico, ripeto, nel quale il pensiero ha da mantenere le sue radici nel corpo e nelle sue emozioni, la mancanza delle quali lo renderebbe pensiero astratto, pensiero macchinico, in realtà non pensiero, ma mera logica combinatoria computazionale di segni.
Un modello guidato da una aisthésis, che trovi nell’espressione artistica una diversa esperienza temporale, nella quale la diacronia rallenta in una contemplazione che, indugiando, la sospende, dandoci accesso per un momento a una forma di eternità: «l’essenza dell’esperienza temporale dell’arte consiste nell’imparare a indugiare. Ciò è forse la contropartita a noi adeguata, cioè finita, di ciò che si chiama eternità» (Gadamer cit. in Han, 2021, p. 59).
Note
1 Nel racconto, Asimov immagina una società completamente dipendente dai computer, che durante una guerra subisce un blackout che li blocca tutti. Gli agenti dello spionaggio americano riescono a trovare e a catturare l’unica persona rimasta al mondo, che sa ancora calcolare le tabelline a memoria e che in questo modo riesce a far continuare la guerra e di sconfiggere i nemici.
2 Vedi wikipedia https://it.wikipedia.org/wiki/Test_di_Turing
3 Il cervello umano può essere considerato un’enorme rete neurale, il cui numero di nodi, chiamati neuroni, è di circa 100 miliardi. Poichè ogni neurone è collegato a migliaia di altri neuroni, abbiamo milioni di miliardi di connessioni. Un neurone biologico è costituito da un corpo cellulare (soma), da molti collegamenti in ingresso (dendriti) e uno in uscita (assone), con il quale il neurone invia informazioni ad altri neuroni, attraverso i loro dendriti. Ogni neurone si attiva quando i segnali che arrivano da altri neuroni attraverso i suoi dendriti, superando una certa soglia propria di ciascun neurone, vengono inviati attraverso il suo assone, ad altri neuroni. Il contatto funzionale tra dentrite e assone, che permette la trasmissione del segnale attraverso un processo elettrochimico, si chiama sinapsi. Questi collegamenti, nei quali risiede la memoria, possono diventare più o meno forti nel tempo (fig. 1).
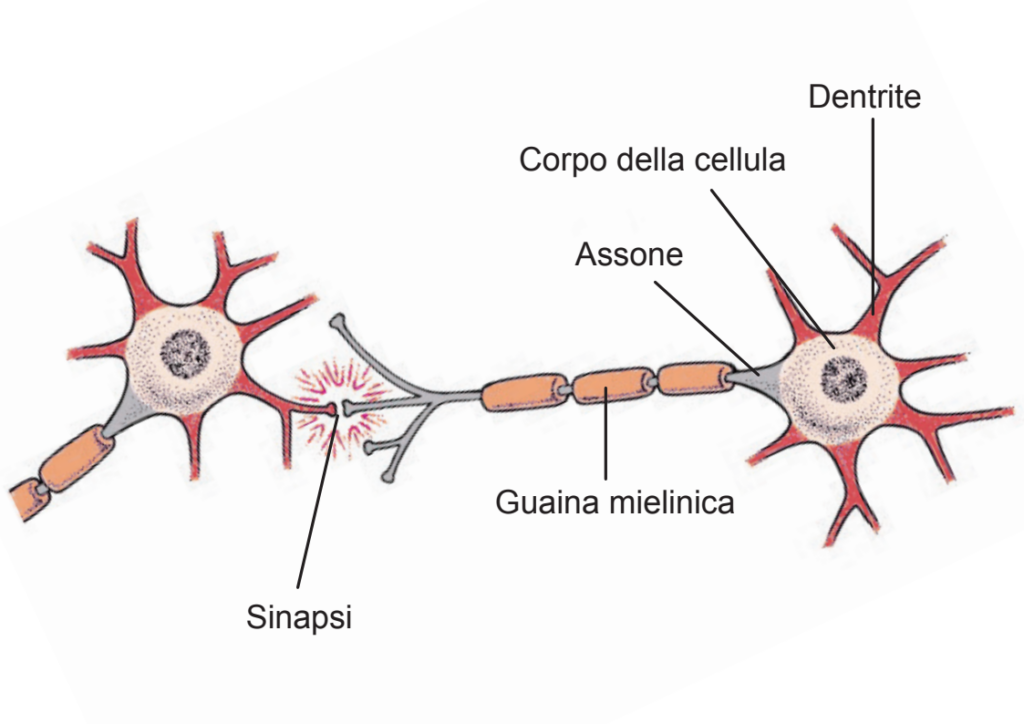
fig. 1
Le reti neurali artificiali hanno solo qualche affinità con quelle biologiche, come la capacità di apprendere, la plasticità e la scomposizione delle informazioni in elementi distribuiti in ogni singolo neurone, i collegamenti tra neuroni “pesati”. I meccanismi di apprendimento del cervello umano non sono stati del tutto chiariti e le reti neurali artificiali sono solo un modo di trattare informazioni in maniera distribuita, attraverso algoritmi di apprendimento.
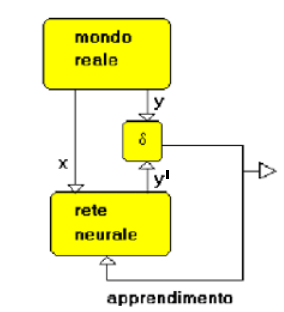
Le reti neurali si distinguono primariamente dal tipo di apprendimento (machine learning) al quale sono sottoposte, che si distingue in supervisionato o non supervisionato. Nel primo caso la rete viene addestrata fornendole esempi di input associati agli output corretti. L’algoritmo di apprendimento a partire dall’input (x), genera un output (y’) che viene confrontato con quello corretto (y), generando un ciclo di retroazione nella rete neurale, che modifica i parametri dell’algoritmo, ovvero i pesi dei collegamenti tra neuroni, a ogni ciclo, dal quale si esce quando lo scarto tra y e y’, assume un valore inferiore a δ, ovvero quando y’ tende a y (fig. 3).
Nell’ambito delle reti neurali addestrate in modo supervisionato, si distinguono quelle associative, che lavorano con valori booleani (0,1) e che sono in grado di fornire gli output associati corretti, a partire da input imprecisi o parziali. Le reti neurali Error Back Propagation (backprop), nello specifico quelle multistrato, hanno invece come dominio valori reali compresi tra 0.0 e 1.0, che le rendono più flessibili rispetto a quelle associative, nell’affrontare problemi reali (fig. 2). Sono quindi associate a una logica fuzzy (o logica sfumata) nella quale si può attribuire a ogni proposizione un grado di verità diverso da 0 e 1 e compreso tra loro. È un’estensione della logica booleana, ovvero una logica polivalente nella quale sono presenti più valori di verità rispetto ai canonici vero, falso. Le backprop sono costituite da uno strato di neuroni di input, uno o più strati di neuroni nascosti e uno strato di neuroni di output. Esse sono in grado di cogliere la funzione matematica che lega l’output con l’input e di usarla per calcolare output risultanti da valori di input diversi da quelli del training set, sia all’interno del range di quest’ultimo (interpolazione) che all’esterno (estrapolazione). La funzione matematica che queste reti individuano, non è però leggibile all’esterno, per cui esse risultano essere delle black boxes. I modelli prodotti delle reti neurali multistrato, che sono quelle più usate per la loro efficacia e flessibilità, non sono quindi spiegabili in linguaggio naturale umano, i loro risultati vanno accettati così come sono. A differenza degli altri sistemi algoritmici che si possono esaminare passo passo dall’input all’output e debuggare, queste reti neurali possono generare risultati altamente attendibili, dei quali però non si può spiegare come e perché siano stati generati.
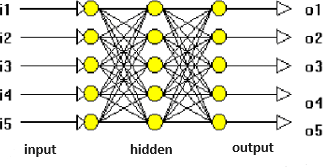
fig. 2
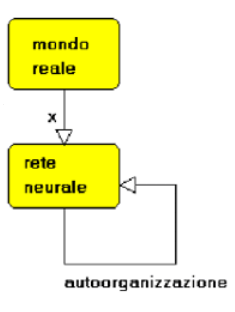
L’apprendimento delle reti neurali non supervisionato, è utilizzato quando non siano disponibili training set che contengano associazioni di input e output corretti, che funzionino da guida per l’addestramento della rete, ma solo input di dati da analizzare e comprendere. Queste reti, chiamate autoorganizzanti, interagiscono con dati in ingresso non ordinati, per identificare, ad esempio, classi di dati con caratteristiche simili alle quali associarli. Una rete, quindi, che si addestra da sé, senza l’aiuto di una supervisione che la guidi attraverso esempi che associano agli input le loro soluzioni (fig. 4).
Fonti: https://www.performancetrading.it/Documents/RNeFL/RNeFL_Index.htm
https://it.wikipedia.org/wiki/Rete_neurale_artificiale
4 Roberto Finelli ritiene che la riduzione del mondo a infosfera ovvero a un massive information process, sia frutto di quella che lui chiama l’ideologia dell’infosfera (Finelli, 2022 e 2024).
5 L’esempio qui sotto appartiene alle correlazioni spurie, ovvero quelle ricavate da accostamenti arbitrari di serie di dati, le cui variabili non hanno alcuna reale interdipendenza tra loro. Il fenomeno delle correlazioni spurie, aumenta all’aumentare della quantità di dati.
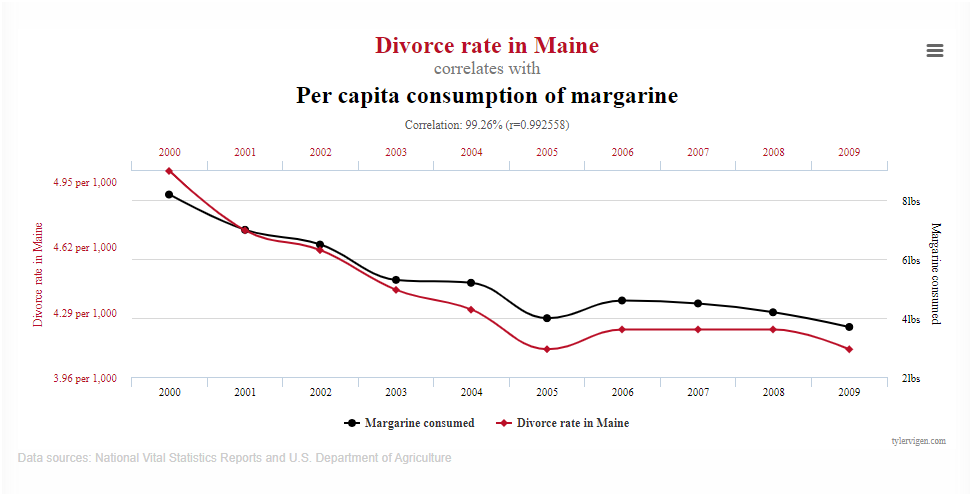
Fonte: https://www.tylervigen.com/spurious-correlations
6 Ruha Benjamin on deep learning: Computational depth without sociological depth is ‘superficial learning’, TECHregister, https://www.techregister.co.uk/ruha-benjamin-on-deep-learning-computational-depth-without-soci ological-depth-is-superficial-learning/
7 https://www.theguardian.com/technology/2023/feb/08/biased-ai-algorithms-racy-women-bodies
8 Berardi F., Il compimento, Nero editions, https://not.neroeditions.com/il-compimento/
9 I trasformatori generativi pre-addestrati (GPT Generative Pretrained Transformer) sono un tipo di modello linguistico di grandi dimensioni (Large Language Model LLM ) e un quadro di riferimento per l’intelligenza artificiale generativa, quella che è in grado di generare testo, audio, immagini e video, in risposta a delle richieste. Sono reti neurali artificiali utilizzate in attività di elaborazione del linguaggio naturale. I GPT si basano sull’architettura informatica dei trasformatori (transformers), vengono pre-addestrati su grandi set di dati di testo e sono in grado di generare nuovi contenuti simili a quelli umani. I transformers sono modelli di apprendimento automatico profondo (deep learning). Fonte Wikipedia https://it.wikipedia.org/wiki/ChatGPT
10 Il chatbot (dove bot è l’abbreviazione di robot) è un software che simula ed elabora le conversazioni umane (scritte o parlate), consentendo agli utenti di interagire con i dispositivi digitali come se stessero comunicando con una persona reale
11 Il bot è un programma che accede alla rete attraverso gli stessi canali adoperati dagli utenti (ad esempio entra in una pagina web, invia un messaggio in una chat piuttosto che in un social media), facendo credere loro di comunicare con un essere umano. Viene anche utilizzato per automatizzare alcune operazioni in rete, troppo complesse per essere svolte dall’utente.
12 Demichelis, L., Ma l’intelligenza artificiale, così com’è, è insostenibile, Agenda Digitale, 2023 https://www.agendadigitale.eu/cultura-digitale/lintelligenza-artificiale-e-ecologicamente-e-socialmente-insostenibile-ecco-perche/
13 Casilli, A., Intelligenza artificiale, l’esercito dei precari, il manifesto, 2023, https://ilmanifesto.it/intelligenza– artificiale-lesercito-dei-precari
14 Mischitelli, L., La guerra “esternalizzata” all’IA: ecco il caos etico, Agenda digitale, 2023, https://www.agenda digitale.eu/sicurezza/esternalizzare-la-guerra-alle-macchine-il-caos-etico/ e Milia, S., Faremo le guerre con l’intelligenza artificiale: come evitare disastri?, Agenda digitale, 2023, https://www.agendadigitale. eu/cultura-digitale/faremo-le-guerre-con-lintelligenza-artificiale-come-evitare-disastri/
15 Per ragioni di spazio, mi limito a rimandare all’ottimo articolo di Deborah De Rosa sulla differenza tra inconscio analogico e inconscio digitale, da una prospettiva freudo lacaniana in https://www.academia.edu/66397322/Dallanalogico_al_digitale_Inconscio_e_linguaggio_nellera_dei_Big_Data
16 Bender E. M., Gebru T., McMillan-Major A., Shmitchell S., On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜 ACM Digital Library 2021, https://dl.acm.org/doi/10.1145/3442188.3445922
17 Le ritenzioni terziarie (che Stiegler fa seguire a quelle primarie e secondarie formulate da Husserl), sono esternalizzazioni psichiche, concrezioni della memoria, esterne alla coscienza, collocate nello spazio su supporti materiali (dalle iscrizioni rupestri alla scrittura digitale), talmente generalizzati e diffusi, che condizionando le ritenzioni primarie della coscienza (quello che la coscienza trattiene e seleziona, nel presente del flusso percettivo), condizionano anche la formazione delle ritenzioni secondarie (i ricordi, ovvero le tracce mnestiche a lungo termine del deposito della memoria), che sono selezioni delle ritenzioni primarie precedenti.
18 Numerico T. Lavoro e pensiero umani, il vero scontro sull’Intelligenza artificiale, ilmanifesto, 2023, https://ilmanifesto.it/lavoro-e-pensiero-umani-il-vero-scontro-sullintelligenza-artificiale
Bibliografia
Alquati, R., Sulla riproduzione della capacità umana vivente. L’industrializzazione della soggettività, DeriveApprodi, Bologna 2021
Deleuze, G., Pourparler, Quodlibet, Macerata 2019
Dick P. K., Ubik, Fanucci, Roma 1988
Finelli R., Filosofia e tecnologia. Una via di uscita dalla mente digitale, Rosenberg & Sellier, Torino 2022
Finelli R., Il dominio dell’esteriore. Filosofia e critica della catastrofe, Rogas, Roma 2024
Floridi L., La quarta rivoluzione. Come l’infosfera sta trasformando il mondo, Raffaello Cortina, Milano 2017
Floridi L., Etica dell’intelligenza artificiale. Sviluppi, opportunità, sfide, Raffaello Cortina, Milano 2022
Gadamer, H. G., L’attualità del bello, Marietti, Genova 1988
Galimberti U., Psiche e techne, Feltrinelli, Milano 1999
Goleman, D., Intelligenza emotiva, Centauria, Milano 2015
Han, B. C., Le non cose. Come abbiamo smesso di vivere il reale, Einaudi, Torino 2022
Han, B. C., La scomparsa dei riti. Una topologia del presente, nottetempo, Milano 2021
Into the black box (a cura di), Capitalismo 4.0 Genealogia della rivoluzione digitale, Meltemi, Milano 2021
Ippolita, Tecnologie del dominio, Meltemi, Milano 2017
Jung, C. G., Il libro rosso, Bollati Boringhieri, Torino 2010
Kuhn T. S., La struttura delle rivoluzioni scientifiche, Einaudi, Torino 2009
Land, N., Meltdown in Fanged Noumena. Collected Writings 1987- 2007, a cura di Mackay R. e Brassier R., Urbanomic, Falmouth 2011, pp. 441-459. Traduzione di Berti P. e De Seta G., Collasso in Lo Sguardo – rivista di filosofia N. 24, 2017 (II) – Limiti e confini del postumano
Marx, K., Lineamenti fondamentali della critica dell’economia politica, II, La Nuova Italia, Firenze 1970.
Michéa, J.-C., Il nostro comune nemico, Neri Pozza, Vicenza 2018 edizione elettronica
Noble, D. F., La questione tecnologica, Bollati Boringhieri, Torino 1993
Numerico, T., Big data e algoritmi. Prospettive critiche, Carocci, Roma 2022
Rouvroy A. Stiegler B., Il regime di verità digitale. Dalla governamentalità algoritmica a un nuovo Stato di diritto, in LA DELEUZIANA – RIVISTA ONLINE DI FILOSOFIA – ISSN 2421-3098 N. 3 / 2016 – LA VITA E IL NUMERO
Sadin, É., Critica della ragione artificiale. Una difesa dell’umanità, LUISS University Press, Roma 2019
Stiegler, B., La società automatica 1. L’avvenire del lavoro, Meltemi, Milano 2019
Stiegler B., La miseria simbolica 1. L’epoca iperindustriale, Meltemi, Milano 2021
Stiegler B., La miseria simbolica 2. La catastrofe del sensibile, Meltemi, Milano 2021